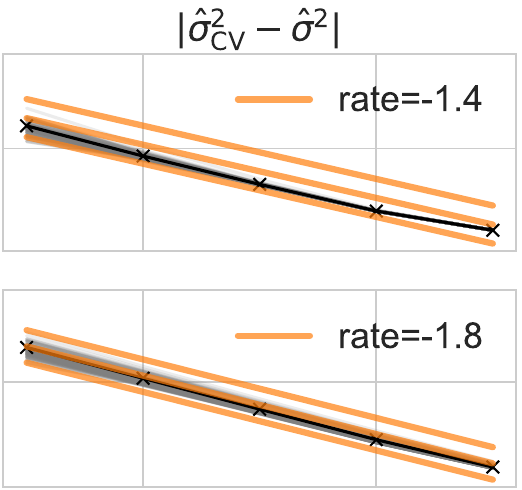
Gaussian process (GP) regression is a Bayesian nonparametric method for regression and interpolation, offering a principled way of quantifying the uncertainties of predicted function values. For the quantified uncertainties to be well-calibrated, however, the covariance kernel of the GP prior has to be carefully selected. In this paper, we theoretically compare two methods for choosing the kernel in GP regression: cross-validation and maximum likelihood estimation. Focusing on the scale-parameter estimation of a Brownian motion kernel in the noiseless setting, we prove that cross-validation can yield asymptotically well-calibrated credible intervals for a broader class of ground-truth functions than maximum likelihood estimation, suggesting an advantage of the former over the latter.
@article{Naslidnyk2023,title={Comparing Scale Parameter Estimators for Gaussian Process Regression: Cross Validation and Maximum Likelihood},author={Naslidnyk, M. and Kanagawa, M. and Karvonen, T. and Mahsereci, M.},arxiv={2307.07466},year={2023},pdf={https://arxiv.org/pdf/2307.07466.pdf},}
Emukit: A Python toolkit for decision making under uncertainty
Paleyes, A.,
Mahsereci, M.,
and Lawrence, N.D.
In Proceedings of the 22nd Python in Science Conference
2023
Emukit is a highly flexible Python toolkit for enriching decision making under uncertainty with statistical emulation. It is particularly pertinent to complex processes and simulations where data are scarce or difficult to acquire. Emukit provides a common framework for a range of iterative methods that propagate well-calibrated uncertainty estimates within a design loop, such as Bayesian optimisation, Bayesian quadrature and experimental design. It also provides multi-fidelity modelling capabilities. We describe the software design of the package, illustrate usage of the main APIs, and showcase the breadth of use cases in which the library already has been used by the research community.
@inproceedings{Paleyes2023,author={Paleyes, A. and Mahsereci, M. and Lawrence, N.D.},title={Emukit: A Python toolkit for decision making under uncertainty},booktitle={Proceedings of the 22nd Python in Science Conference},pages={68 - 75},year={2023},pdf={https://conference.scipy.org/proceedings/scipy2023/pdfs/emukit.pdf},}
2021
ProbNum: Probabilistic Numerics in Python
Wenger, J.,
Krämer, N.,
Pförtner, M.,
Schmidt, J.,
Bosch, N.,
Effenberger, N.,
Zenn, J.,
Gessner, A.,
Karvonen, T.,
Briol, F-X,
Mahsereci, M.,
and Hennig, P.
Probabilistic numerical methods (PNMs) solve numerical problems via probabilistic inference. They have been developed for linear algebra, optimization, integration and differential equation simulation. PNMs naturally incorporate prior information about a problem and quantify uncertainty due to finite computational resources as well as stochastic input. In this paper, we present ProbNum: a Python library providing state-of-the-art probabilistic numerical solvers. ProbNum enables custom composition of PNMs for specific problem classes via a modular design as well as wrappers for off-the-shelf use. Tutorials, documentation, developer guides and benchmarks are available online at www.probnum.org.
@article{Wenger2021,title={ProbNum: Probabilistic Numerics in Python},author={Wenger, J. and Krämer, N. and Pf{\"o}rtner, M. and Schmidt, J. and Bosch, N. and Effenberger, N. and Zenn, J. and Gessner, A. and Karvonen, T. and Briol, F-X and Mahsereci, M. and Hennig, P.},arxiv={2112.02100},year={2021},pdf={https://arxiv.org/pdf/2112.02100.pdf},}
Invariant Priors for Bayesian Quadrature
Naslidnyk, M.,
Gonzalez, J.,
and Mahsereci, M.
In Your Model is Wrong: Robustness and misspecification in probabilistic modeling Workshop, NeurIPS
2021
Accepted as contributed talk.
Bayesian quadrature (BQ) is a model-based numerical integration method that is able to increase sample efficiency by encoding and leveraging known structure of the integration task at hand. In this paper, we explore priors that encode invariance of the integrand under a set of bijective transformations in the input domain, in particular some unitary transformations, such as rotations, axis-flips, or point symmetries. We show initial results on superior performance in comparison to standard Bayesian quadrature on several synthetic and one real world application.
@inproceedings{Naslidnyk2021,title={Invariant Priors for Bayesian Quadrature},author={Naslidnyk, M. and Gonzalez, J. and Mahsereci, M.},booktitle={Your Model is Wrong: Robustness and misspecification in probabilistic modeling Workshop, NeurIPS},year={2021},pdf={https://arxiv.org/pdf/2112.01578.pdf},}
Dynamic Pruning of a Neural Network via Gradient Signal-to-Noise Ratio
Siems, J.N.,
Klein, A.,
Archambeau, C.,
and Mahsereci, M.
In 8th ICML Workshop on Automated Machine Learning (AutoML)
2021
While training highly overparameterized neural networks is common practice in deep learning, research into post-hoc weight-pruning suggests that more than 90% of parameters can be removed without loss in predictive performance. To save resources, zero-shot and one-shot pruning attempt to find such a sparse representation at initialization or at an early stage of training. Though efficient, there is no justification, why the sparsity structure should not change during training. Dynamic sparsity pruning undoes this limitation and allows to adapt the structure of the sparse neural network during training. In this work we propose to use the gradient noise to make pruning decisions. The procedure enables us to automatically adjust the sparsity during training without imposing a hand-designed sparsity schedule, while at the same time being able to recover from previous pruning decisions by unpruning connections as necessary. We evaluate our method on image and tabular datasets and demonstrate that we reach similar performance as the dense model from which the sparse network is extracted, while exposing less hyperparameters than other dynamic sparsity methods.
@inproceedings{Siems2021,title={Dynamic Pruning of a Neural Network via Gradient Signal-to-Noise Ratio},author={Siems, J.N. and Klein, A. and Archambeau, C. and Mahsereci, M.},booktitle={8th ICML Workshop on Automated Machine Learning (AutoML) },year={2021},pdf={https://openreview.net/pdf?id=34awaeWZgya},}
2020
A Fourier State Space Model for Bayesian ODE Filters
Kersting, H.,
and Mahsereci, M.
In Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models, ICML
2020
Gaussian ODE filtering is a probabilistic numerical method to solve ordinary differential equations (ODEs). It computes a Bayesian posterior over the solution from evaluations of the vector field defining the ODE. Its most popular version, which employs an integrated Brownian motion prior, uses Taylor expansions of the mean to extrapolate forward and has the same convergence rates as classical numerical methods. As the solution of many important ODEs are periodic functions (oscillators), we raise the question whether Fourier expansions can also be brought to bear within the framework of Gaussian ODE filtering. To this end, we construct a Fourier state space model for ODEs and a ‘hybrid’ model that combines a Taylor (Brownian motion) and Fourier state space model. We show by experiments how the hybrid model might become useful in cheaply predicting until the end of the time domain.
@inproceedings{KerstingMahsereci2020,author={Kersting, H. and Mahsereci, M.},title={A {Fourier} State Space Model for {Bayesian} {ODE} Filters},year={2020},booktitle={Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models, ICML},pdf={https://arxiv.org/pdf/2007.09118.pdf},}
Active Multi-Information Source Bayesian Quadrature
Gessner, A.,
Gonzalez, J.,
and Mahsereci, M.
In Proceedings of The 35th Uncertainty in Artificial Intelligence Conference
22–25 jul
2020
Bayesian quadrature (BQ) is a sample-efficient probabilistic numerical method to solve integrals of expensive-to-evaluate black-box functions, yet so far, active BQ learning schemes focus merely on the integrand itself as information source, and do not allow for information transfer from cheaper, related functions. Here, we set the scene for active learning in BQ when multiple related information sources of variable cost (in input and source) are accessible. This setting arises for example when evaluating the integrand requires a complex simulation to be run that can be approximated by simulating at lower levels of sophistication and at lesser expense. We construct meaningful cost-sensitive multi-source acquisition-rates as an extension to common utility functions from vanilla BQ (VBQ), and discuss pitfalls that arise from blindly generalizing. In proof-of-concept experiments we scrutinize the behavior of our generalized acquisition functions. On an epidemiological model, we demonstrate that active multi-source BQ (AMS-BQ) is more cost-efficient than VBQ in learning the integral to a good accuracy.
@inproceedings{Gessner2019,title={Active Multi-Information Source Bayesian Quadrature},author={Gessner, A. and Gonzalez, J. and Mahsereci, M.},booktitle={Proceedings of The 35th Uncertainty in Artificial Intelligence Conference},pages={712--721},year={2020},editor={Adams, Ryan P. and Gogate, Vibhav},volume={115},series={Proceedings of Machine Learning Research},month={22--25 Jul},publisher={PMLR},pdf={http://proceedings.mlr.press/v115/gessner20a.}
2019
Emulation of physical processes with Emukit
Paleyes, A.,
Pullin, M.,
Mahsereci, M.,
Lawrence, N.,
and Gonzalez, J.
In Second Workshop on Machine Learning and the Physical Sciences, NeurIPS
2019
Decision making in uncertain scenarios is an ubiquitous challenge in real world systems. Tools to deal with this challenge include simulations to gather information and statistical emulation to quantify uncertainty. The machine learning community has developed a number of methods to facilitate decision making, but so far they are scattered in multiple different toolkits, and generally rely on a fixed backend. In this paper, we present Emukit, a highly adaptable Python toolkit for enriching decision making under uncertainty. Emukit allows users to: (i) use state of the art methods including Bayesian optimization, multi-fidelity emulation, experimental design, Bayesian quadrature and sensitivity analysis; (ii) easily prototype new decision making methods for new problems. Emukit is agnostic to the underlying modeling framework and enables users to use their own custom models. We show how Emukit can be used on three exemplary case studies.
@inproceedings{Paleyes2019,author={Paleyes, A. and Pullin, M. and Mahsereci, M. and Lawrence, N. and Gonzalez, J.},title={Emulation of physical processes with Emukit},booktitle={Second Workshop on Machine Learning and the Physical Sciences, NeurIPS},year={2019},pdf={https://ml4physicalsciences.github.io/2019/files/NeurIPS_ML4PS_2019_113.pdf},}
2018
On Acquisition Functions for Active Multi-Source Bayesian Quadrature
Gessner, A.,
Gonzalez, J.,
and Mahsereci, M.
In All of Bayesian Nonparametrics Workshop, NeurIPS
2018
Bayesian quadrature (bq) is the method of choice for solving integrals of expensive-to-evaluate black-box functions. Active learning schemes so far only focus on the integrand itself, and do not allow for incorporation of cheaper, related information sources. Here, we set the scene for active learning in Bayesian quadrature when multiple related information sources of variable cost (in input and source) are accessible. In vanilla-bq (vbq) the same active learning scheme is induced by several measures of gain on the integral estimation. We show that this degeneracy is lifted in the multi-source setting, in which the previously interchangeably used vbq utilities yield different active learning schemes. In proof-of-concept experiments we scrutinize the behavior of our generalized acquisition functions.
@inproceedings{Gessner2018,author={Gessner, A. and Gonzalez, J. and Mahsereci, M.},title={On Acquisition Functions for Active Multi-Source Bayesian Quadrature},booktitle={All of Bayesian Nonparametrics Workshop, NeurIPS},year={2018},pdf={https://d39w7f4ix9f5s9.cloudfront.net/aa/b2/50a316984beab1dd39244efc1f7d/scipub-272.pdf},}
Probabilistic Approaches to Stochastic Optimization
@phdthesis{Mahsereci2018,title={Probabilistic Approaches to Stochastic Optimization},author={Mahsereci, M.},school={Eberhard Karls Universit{\"a}t T{\"u}bingen, Germany},year={2018},doi={http://dx.doi.org/10.15496/publikation-26116},}
2017
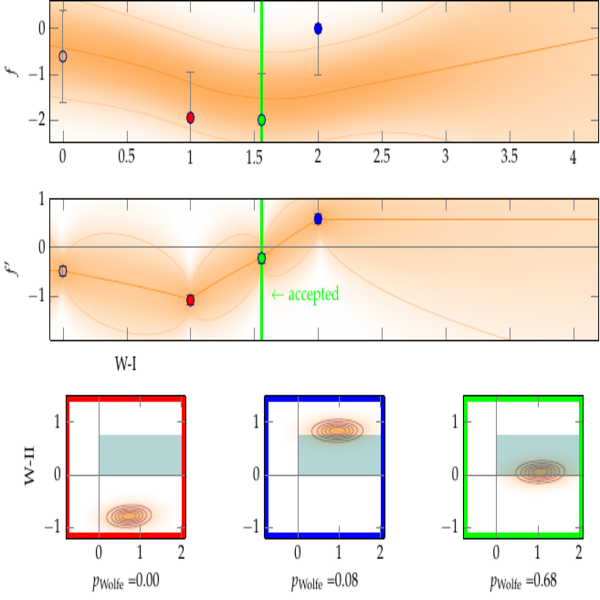
Probabilistic Line Searches for Stochastic Optimization
In deterministic optimization, line searches are a standard tool ensuring stability and efficiency. Where only stochastic gradients are available, no direct equivalent has so far been formulated, because uncertain gradients do not allow for a strict sequence of decisions collapsing the search space. We construct a probabilistic line search by combining the structure of existing deterministic methods with notions from Bayesian optimization. Our method retains a Gaussian process surrogate of the univariate optimization objective, and uses a probabilistic belief over the Wolfe conditions to monitor the descent. The algorithm has very low computational cost, and no user- controlled parameters. Experiments show that it effectively removes the need to define a learning rate for stochastic gradient descent.
@article{Mahsereci2017b,author={Mahsereci, M. and Hennig, P.},title={Probabilistic Line Searches for Stochastic Optimization},journal={Journal of Machine Learning Research},year={2017},volume={18},number={119},pages={1-59},pdf={https://jmlr.csail.mit.edu/papers/volume18/17-049/17-049.pdf},}
Early Stopping Without a Validation Set
Mahsereci, M.,
Balles, L.,
Lassner, C.,
and Hennig, P.
Early stopping is a widely used technique to prevent poor generalization performance when training an over-expressive model by means of gradient-based optimization. To find a good point to halt the optimizer, a common practice is to split the dataset into a training and a smaller validation set to obtain an ongoing estimate of the generalization performance. We propose a novel early stopping criterion based on fast-to-compute local statistics of the computed gradients and entirely removes the need for a held-out validation set. Our experiments show that this is a viable approach in the setting of least-squares and logistic regression, as well as neural networks.
@article{Mahsereci2017a,title={Early Stopping Without a Validation Set},author={Mahsereci, M. and Balles, L. and Lassner, C. and Hennig, P.},arxiv={1703.09580},year={2017},pdf={https://arxiv.org/pdf/1703.09580.pdf},}
Automating Stochastic Optimization with Gradient Variance Estimates
One reason optimization methods might have to expose free parameters to the user, rather than to set them internally, is that these parameters are not identifiable given the “observations” available to the method. We discuss the use of gradient variance estimates as an additional source of information allowing for automation of stochastic optimization algorithms. We review several recent results that use such estimates to eliminate (i.e., determine internally, without user intervention) hyper-parameters of stochastic optimizers and contribute a detailed discussion of the efficient implementation of gradient variance estimates for neural networks.
@article{Balles2017,author={Balles, L. and Mahsereci, M. and Hennig, P.},title={Automating Stochastic Optimization with Gradient Variance Estimates},journal={AutoML Workshop, ICML},year={2017},pdf={https://7bce9816-a-62cb3a1a-s-sites.googlegroups.com/site/automl2017icml/accepted-papers/AutoML_2017_paper_6.pdf?attachauth=ANoY7cq6kv_KSergf07tEvRAgtMZxioI5VJzpW0RCbX73jdWHIJi9UVTpkLufRzx8cgpYUi3rrrvT6gNHohQ7dHZv6duOYUjrPSNSDK_EpskgjtOxAA4nlEY48Sy2v_QsfEaFatZmdXfP-M43RzAWEE4rB8qq5sE-Q0mfA89auEEeHknxHbcsqPjX_zi8bDI_oEs5XpzDZsUpw8tK9FvKsPRixHMUEaQR3Yvj1NVk9yWcPua7gzBIcsebE8DGhnRhDZ-NC2-4Onu&attredirects=0},}
2015
Probabilistic Line Searches for Stochastic Optimization
Mahsereci, M.,
and Hennig, P.
In Advances in Neural Information Processing Systems 28
2015
Selected as full oral (< 1% acceptance).
In deterministic optimization, line searches are a standard tool ensuring stability and efficiency. Where only stochastic gradients are available, no direct equivalent has so far been formulated, because uncertain gradients do not allow for a strict sequence of decisions collapsing the search space. We construct a probabilistic line search by combining the structure of existing deterministic methods with notions from Bayesian optimization. Our method retains a Gaussian process surrogate of the univariate optimization objective, and uses a probabilistic belief over the Wolfe conditions to monitor the descent. The algorithm has very low computational cost, and no user-controlled parameters. Experiments show that it effectively removes the need to define a learning rate for stochastic gradient descent.
@inproceedings{Mahsereci2015,title={Probabilistic Line Searches for Stochastic Optimization},author={Mahsereci, M. and Hennig, P.},booktitle={Advances in Neural Information Processing Systems 28},pages={181--189},editors={C. Cortes, N.D. Lawrence, D.D. Lee, M. Sugiyama and R. Garnett},publisher={Curran Associates, Inc.},year={2015},pdf={http://papers.nips.cc/paper/5753-probabilistic-line-searches-for-stochastic-optimization.pdf},}